
Did you know? The global multiomics market size is projected to jump from USD3.9 billion in 2024 to USD15.3 billion by 2034, a 14.8%CAGR. This rapid growth shows a major shift in how we study biological systems and create treatments. Traditional single-omics methods, though useful, only offer partial views of the complex processes behind cellular function and disease.
Today’s biggest challenges in drug discovery and personalized medicine require a broader understanding of biology. Multi-omics, which combines different types of molecular data, helps meet this need by providing a complete picture of biological systems, leading to better decisions and faster breakthroughs.
In this article, we explore the transformative potential of multi-omics data analysis and integration, examining how pharmaceutical and biotech companies can leverage these approaches to enhance drug discovery pipelines, improve therapeutic targeting, and ultimately deliver more effective treatments to patients.
Key Takeaways
- Multi-omics data integration enables deeper biological insights, helping pharma and biotech companies optimize drug discovery and deliver more effective therapies by merging genomics, transcriptomics, proteomics, metabolomics, and epigenomics data.
- Robust pipelines, strong technical QC, batch effect mitigation, and scalable analytics platforms are essential for reliable multi-omics research and successful regulatory submissions.
- Integration strategies range from early (feature-level) to late (prediction-level), each offering distinct trade-offs in interpretability, computation, and suitability for different real-world use cases.
- Cloud-based and AI-driven platforms have become standard to manage the complexity and scale of multi-omics data, supporting reproducibility, secure collaboration, and compliance.
- Key challenges remain, especially in managing data volume, complexity, cost, and regulatory requirements, making robust infrastructure and unified solutions critical for industrial adoption.
What is Omics Data?
Omics data represents the comprehensive characterization of molecular components within biological systems. The term encompasses large-scale datasets that capture the entirety of specific molecular classes, from the complete genetic blueprint encoded in DNA to the dynamic protein landscape that executes cellular functions.
Each omics layer provides unique insights into biological processes, offering distinct perspectives on how cells function, respond to stimuli, and contribute to health or disease states.
| Omics Layer | Molecular Focus | Typical Readout | Key Questions Answered | Primary Technologies |
| Genomics | DNA sequence and structure | Variants, CNVs | Inherited risk, mutational signatures | NGS, long-read sequencing |
| Transcriptomics | RNA expression | mRNA, lncRNA counts | Active genes, splice variants | RNA-Seq, scRNA-Seq |
| Proteomics | Protein abundance & PTMs | Peptides, PTMs | Cellular machinery, drug targets | LC-MS/MS, DIA-MS |
| Metabolomics | Small molecules & lipids | Metabolite concentrations | Pathway activity, metabolic flux | LC/GC-MS, NMR |
| Epigenomics | Chromatin state & marks | DNA methylation, histone marks | Gene regulation dynamics | ATAC-Seq, bisulfite-Seq |
Why Multi-omics Data Matters
The productivity crisis of modern pharma companies, such as soaring R&D costs with stagnant success rates, stems partly from an incomplete biological context.
Multi-omics delivers the multi-layered perspective needed to de-risk target selection, uncover resistance pathways, and define molecular endotypes that align treatments with responders. Companies embedding multi-omics have reported:
- 2-3× improvement in target validation confidence versus single-omic screens.
- Up to 30% faster enrolment in trials using multi-omic signatures for patient pre-screening.
- 70% of FDA-approved drugs since 2015 show genomic evidence of efficacy; multi-omics expands this evidence across protein and metabolite layers, further raising success odds.
The diversity of omics approaches offers unique opportunities to understand biological complexity. However, to fully harness multi-omics, systematic data collection and processing are essential to maintain molecular integrity and support large-scale analysis.
Data Collection and Processing of Multi-omics Data
Efficient multi-omics begins well before data analysis. It starts with protocols designed to preserve sample quality and regulatory compliance. Here’s a practical walk-through of each core step.
| Step | What Happens | Key Tip | Pitfall to Avoid |
| Collection | Biosamples (fresh tissue, blood, FFPE blocks, single cells) are gathered for downstream omics workflows. | Use ISO-compliant preservatives to safeguard sample integrity and future-proof consent for re-analysis. | Poor time-to-freeze or inconsistent handling can degrade sensitive molecules, especially problematic for metabolomics. |
| Wet-Lab Prep | Extract DNA/RNA, prepare libraries, and perform mass spectrometry runs. | Always include quality controls: ERCC spikes for RNA, NIST reference plasma for metabolites, to ensure batch-to-batch comparability. | Inadequate controls make it difficult to detect (or correct) drift and batch effects. |
| Sequencing / MS Acquisition | Generate raw data using high-throughput instruments (NovaSeq, PromethION, Orbitrap, Q-TOF). | Aim for high-quality metrics, such as Q30 for sequencing (≥85% bases), and FDR ≤1% for peptide identification in proteomics. | Delays or equipment queues risk temperature artifacts, undermining data reliability. |
| Pipeline Processing | Data is transformed through alignment, quantification, rigorous QC, and export into standardized formats (Nextflow, Cromwell, DRAGEN). | Use containerized, version-controlled workflows and store outputs in scalable formats (HDF5, Parquet) for reproducibility and analysis. | “Snowflake” pipelines and one-off scripts undermine scalability and regulatory compliance. |
| Integration & Analytics | Multi-omics datasets are harmonized and modeled (MOFA, graph neural networks, AutoML, federated learning). | Begin with unsupervised models to explore shared biology, and progress to machine learning for robust predictions. | Naively merging raw features overlooks batch and scale differences between modalities. |
By systematically progressing through these phases, with attention to detail at each step, organizations can prevent costly pitfalls and extract the full value from their multi-omics investment.
With your data now reliably generated and standardized, the next challenge is to ensure that technical anomalies don’t obscure the biological signal. This is where advanced approaches to batch effect mitigation come in.
Eliminating Batch Effects
Large pharma trials run across multiple sites and extended timeframes, making them especially vulnerable to “batch effects”—spurious technical variation that can masquerade as biology. The biotech industry now employs sophisticated statistical correction methods and meticulous quality control to keep results on track.
Key methods include:
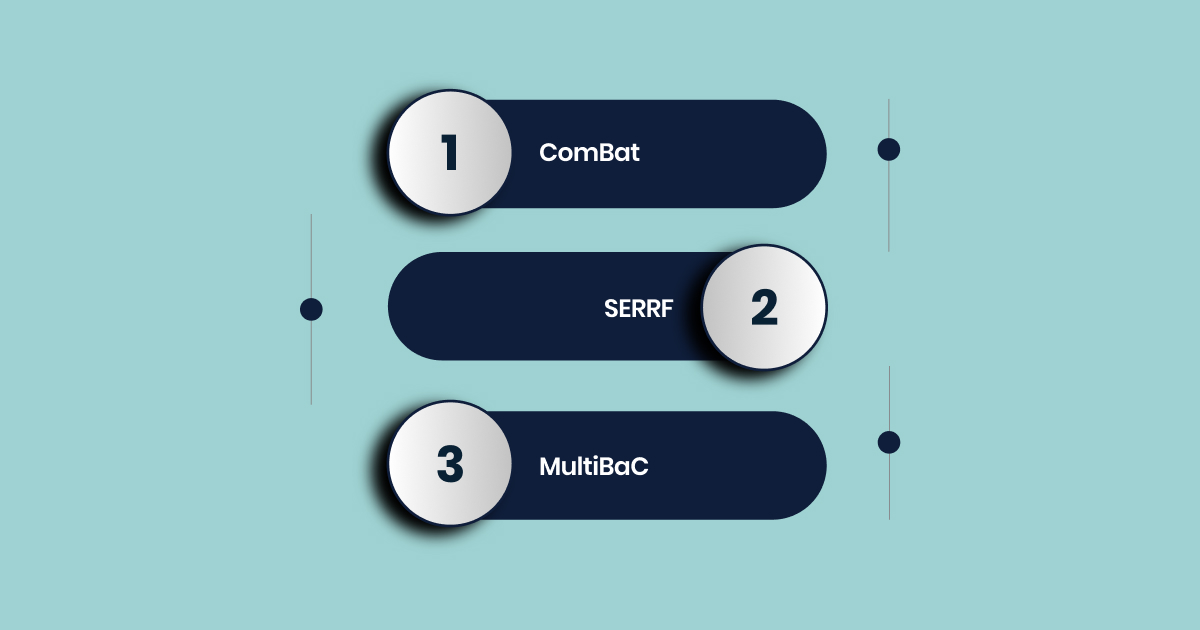
- ComBat: Uses empirical Bayes statistics to harmonize data across batches, especially effective for high-dimensional datasets like those in transcriptomics and proteomics.
- SERRF: Quality-control sample drift modeling, particularly for metabolomic runs, to correct for time-dependent shifts.
- MultiBaC: Joint factor correction across modalities, essential when multiple omics layers share underlying (but unmeasured) technical variance.
For example, Roche’s Tumor Profiler project successfully applied ComBat across nine analytic platforms, slashing inter-batch variance by 35% and improving predictive model performance by 20% AUROC.
Once batch effects are neutralized, multi-omics data is ready for integration and large-scale computational analysis, the true engine behind modern precision medicine.
Integration Strategies for Multi-omics Data
The full potential of multi-omics is realized when diverse molecular data are combined into comprehensive models that offer deeper insights than individual omics layers.
Integration must overcome challenges like data differences, scale variations, and biological complexity while maintaining meaningful signals.
Multi-omics integration falls into three tactical steps. Each serves a distinct purpose, carries unique pitfalls, and maps onto specific development stages.
| Strategy | Typical Algorithms | Pros | Cons | Use Cases |
| Early | PCA, t-SNE, Elastic Net | Fast; interpretable | Batch effects, feature imbalance | Transcriptome-metabolome synergy screens |
| Intermediate | MOFA, JIVE, VAEs | Captures shared & private factors | Compute-intensive | Tumor immune subtyping for ICI trials |
| Late | Random Forest, SNF, DNN stacking | Modular; GDPR-friendly | Limited cross-talk capture | Network-level fusion for neuroblastoma prognosis |
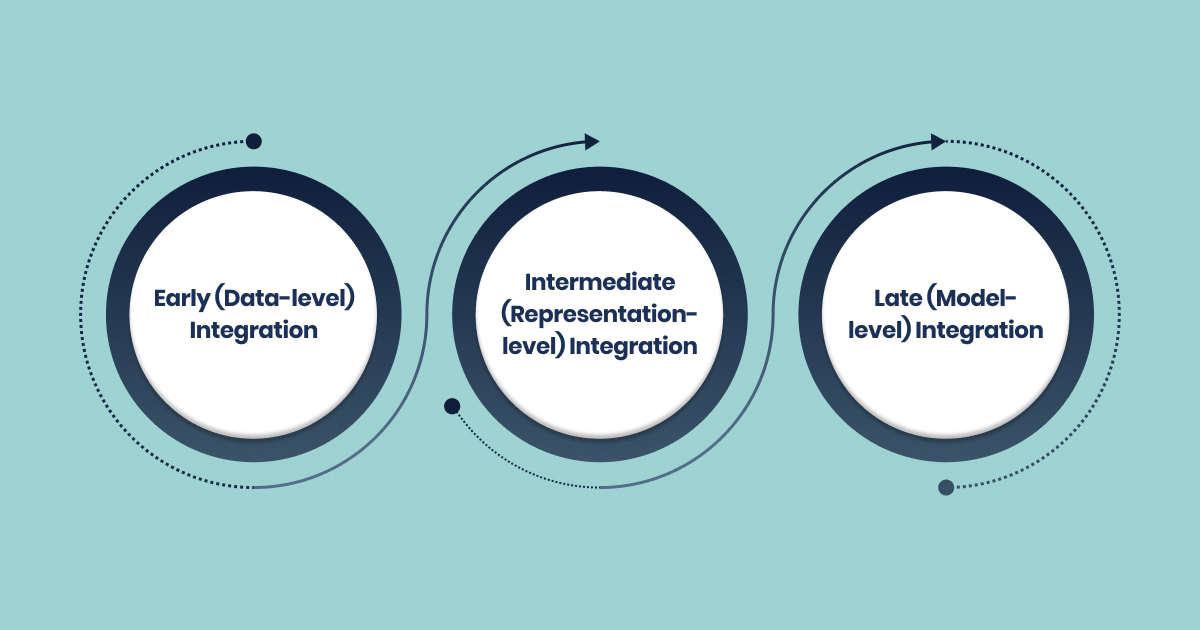
1. Early (Data-level) Integration
Raw feature matrices from each omics layer are concatenated, followed by global normalization and dimensionality reduction.
- Strengths: Simple; maximizes data variance; feeds directly into ML classifiers.
- Pitfalls: Dominance of high-variance assays (e.g., RNA-seq) can obscure metabolomic or proteomic signals unless feature scaling is rigorously applied.
2. Intermediate (Representation-level) Integration
Algorithms jointly learn latent embeddings that capture covariance across modalities (e.g., MOFA, Joint NMF, VAEs).
- Strengths: Handles missing modalities; supports unsupervised discovery of disease subtypes.
- Pitfalls: Requires extensive hyperparameter tuning and large annotated cohorts for stability.
3. Late (Model-level) Integration
Separate predictive models are trained per omics block; outputs are fused via stacked ensembles, voting schemes, or network-based similarity fusion.
- Strengths: Allows assay-specific QC and regulatory traceability; useful when data access is tiered across CROs.
- Pitfalls: Disjoint training can lose cross-layer interactions critical for pathway biology.Cloud & AI: The New Default
Once you understand which tier fits your use case, the next step is selecting or building platforms that operationalize that tier.
Below is a snapshot of leading toolkits aligned with each strategy. The notes explain how each platform mitigates real-world constraints such as HIPAA compliance or GMP readiness.
| Platform | Integration Tier | Key Capabilities | Pharma-Grade Features |
| Omics Fusion | Early | Web-based QC, pathway & heat-map visualizations | Audit logs, ISO 27001 hosting |
| mixOmics / DIABLO | Intermediate | Sparse PLS-DA, cross-block correlation plots | R/CLI dual interfaces; Docker images for reproducibility |
| MOFA + | Intermediate | Probabilistic latent factors, missing-data handling | GPU acceleration; Snakemake pipelines for 21 CFR Part 11 traceability |
| Similarity Network Fusion (SNF) | Late | Patient-level graph fusion, survival prediction | Compatible with federated-learning toolkits; modular encryption |
| Norstella LinQ | Late | Omics-claims-EHR linkage, payer analytics | GDPR-compliant de-identification; pay-per-use APIs |
Cloud & AI: The New Default
As data volumes balloon, so do infrastructure requirements. Cloud-first strategies and AI-powered analytics are now standard in bio-pharma, enabling not only storage and computing at scale but also secure collaboration and compliance with data privacy laws.
| Platform | Cloud | Differentiator | Pharma Use Case |
| FireCloud / Terra | Meets FISMA-moderate compliance; natively supports WDL workflows for reproducibility and traceability. | Genomic analysis for NCI Cancer Moonshot, handling sensitive, large-scale datasets. | |
| AtoMx SIP | AWS | Advanced analytics for spatial omics, including image-derived data. | Driving NanoString’s CDx developments by integrating spatial transcriptomics and protein markers. |
| HiOmics SaaS | Multi-cloud | Ships with 300+ Dockerized plugins for diverse QC and analytic tasks, making it turnkey for smaller biotechs. | End-to-end support for QC, analysis, and reporting without specialized IT overhead or silos. |
Cutting-edge devices like ONT’s MinION also let you stream real-time sequencing directly to the cloud, bypassing historical cold-chain constraints and enabling same-day analysis.
The confluence of meticulous technical QC, batch correction, and industrialized analytics platforms sets the stage for translating data into measurable business and clinical value.
Business Wins That Move the Needle
Multi-omics integration has moved beyond academic pilot studies. It’s now driving commercial deals, accelerating trial designs, and improving patient outcomes. Notable industrial results demonstrate the power of these technologies:
- Bio-Techne’s liquid biopsy platform merged cell-free DNA methylation with exosome-associated RNA and protein markers, reaching 92% sensitivity and 89% specificity for colorectal cancer. This enabled three new pharma companion diagnostic partnerships in 2024.
- AstraZeneca equipped its oncology pipeline with multi-omic spatial imaging, trimming six months off drug target validation cycles, crucial in a competitive market.
- MultiOmic Health deployed AI to integrate metabolomic and transcriptomic clusters, stratifying diabetic kidney disease patients and optimizing Phase II trial design with fewer patients, less time, and clearer endpoints.
Regulatory approval and cross-trial consistency require that these technical wins are underpinned by standardized quality control and harmonized reporting frameworks.
Regulatory & QC Cheat-Sheet
Evolving standards and expectations from regulatory agencies match the push for multi-omics. Staying ahead means understanding and implementing the latest guidelines for quality assurance and transparent reporting.
- ISO 88532:2025: Sets requirements for batch traceability, cross-platform validation, and minimum read depth—consider these non-negotiable for large-scale trials.
- FDA Multi-Component Biomarker Draft: Clarifies terminology (e.g., “panel,” “signature,” “score”) to ensure that all omics-based companion diagnostics are reviewed against clear benchmarks.
- Reference materials: Incorporating ERCC spike-ins (for transcriptomics) and NIST SRM 1950 plasma samples (for metabolomics) provides anchored, auditable standards for every batch.
| Standard or Tool | Role in QC | Impact |
| ISO 88532:2025 | Cross-platform QC, minimum depth, traceability | Ensures regulatory acceptance and reproducibility across trials |
| ERCC/NIST standards | Batch effect diagnosis and normalization | Confers reliability to findings, supports bridging studies |
| FDA multi-component lexicon | Harmonized nomenclature for submissions | Smoother filings, fewer regulatory setbacks |
While advanced analytical methods offer powerful tools for multi-omics, their real-world application in pharma and biotech faces practical challenges. Understanding these hurdles is key to success.
The gap between what these tools can theoretically do and what’s needed for real-world implementation often decides whether multi-omics initiatives succeed or fail.
Challenges with Multi-omics Data
Multi-omics holds immense potential to revolutionize pharmaceutical research and drug development. However, several challenges hinder its widespread adoption and success. These obstacles span technical, computational, and practical domains, impacting timelines, costs, and success rates.
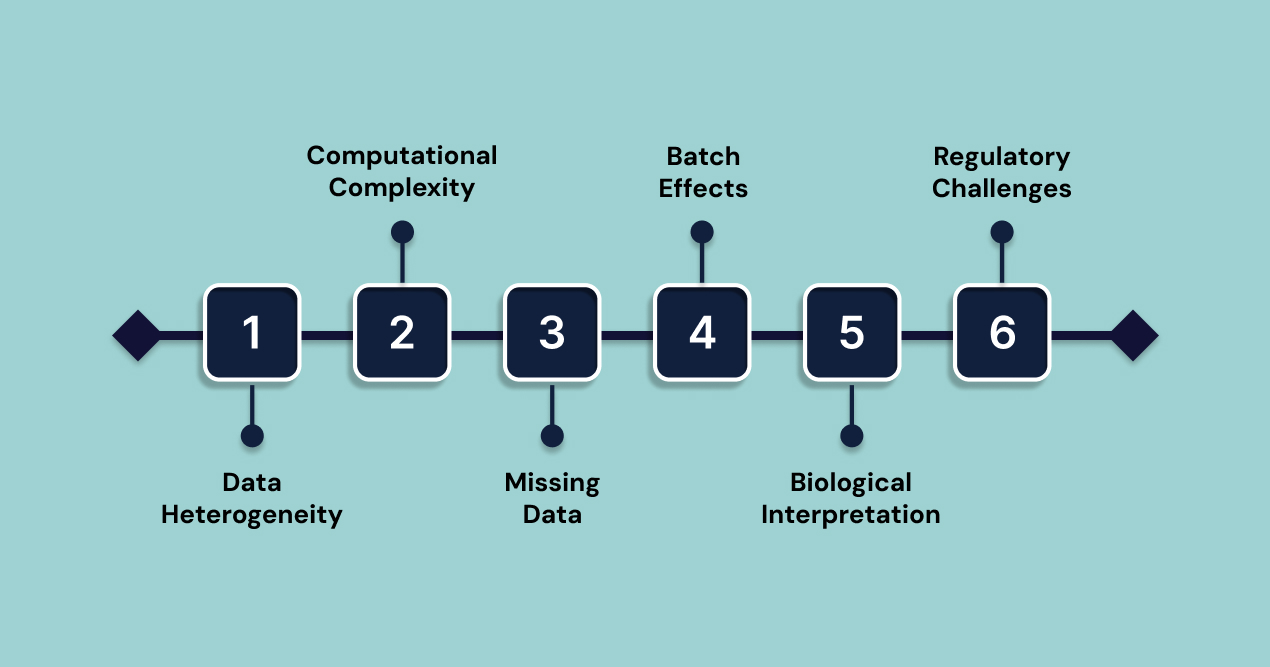
- Data Heterogeneity and Standardization
Different omics technologies generate data with varying characteristics, scales, and distributions. Genomic data consists of discrete variants, transcriptomic data involves continuous expression values, and proteomic and metabolomic data face issues like missing values and detection sensitivities. These differences complicate integration and biological interpretation.
- Computational Complexity and Resource Demands
The combination of multiple high-dimensional datasets requires advanced computational infrastructure. Multi-omics studies demand large storage capacities, often reaching terabytes or petabytes, and high-performance computing that many organizations cannot easily afford or maintain.
- Missing Data and Incomplete Measurements
Missing data across omics layers complicates integration and can introduce bias. Technical limitations, sample quality, and cost constraints often lead to incomplete data matrices, reducing the power of integrative analysis.
- Batch Effects and Technical Variability
Systematic differences between batches, such as variations in processing conditions, can obscure biological signals. Identifying and correcting these batch effects requires sophisticated statistical methods and careful experimental design.
- Biological Interpretation Complexity
Integrating multiple omics layers uncovers complex patterns spanning different molecular pathways. Interpreting these findings requires extensive domain expertise and advanced analytical tools to translate them into actionable insights.
- Regulatory and Validation Challenges
Regulatory agencies demand rigorous validation for multi-omics biomarkers. The complex integration methods used in multi-omics can be difficult to validate using existing frameworks, which were designed for simpler tests.
Overcoming these obstacles is exactly where a vertically integrated platform like Biostate AI excels.
How Integrating Biostate AI Can Improve Your Multi-omics Data Analysis
Multi-omics projects often stall due to fragmented workflows, spiraling costs, and scarce bioinformatics talent. Biostate AI remedies these pain points with a unified solution.
We offer:
- Complete RNA Sequencing Solution: High-quality total RNA sequencing starting at $80 per sample with rapid 1-3 week turnaround times, supporting diverse sample types including blood, tissue, culture, and purified RNA with minimal sample requirements (10µL blood, 10ng RNA, or 1 FFPE slide).
- Advanced Multi-omics Integration: The OmicsWeb platform provides seamless integration of RNA-Seq data with other omics layers, including genomics, proteomics, and metabolomics, enabling comprehensive molecular profiling without requiring specialized bioinformatics expertise.
- AI-Powered Analysis: Integrated AI copilot enables natural language queries for data exploration and analysis, while automated analytical pipelines transform raw multi-omics data into publication-ready insights and actionable biological interpretations.
- Low-Quality Sample Compatibility: Unique capability to process degraded RNA samples with RIN scores as low as 2, compared to typical requirements of RIN ≥5, dramatically expanding the range of usable clinical samples and archived specimens.
- Disease Prediction Capabilities: Biobase foundational model leverages integrated multi-omics data to predict drug toxicity with 89% accuracy and therapy selection with 70% accuracy, providing unprecedented insights for pharmaceutical applications.
- Cost-Effective Scalability: Streamlined workflows and automated processing reduce the per-sample cost to just $80 while maintaining high-quality results, making large-scale multi-omics studies economically feasible for organizations of all sizes.
Armed with practical tactics and a capable partner, you now have a clear path to extract maximum value from integrated omics.
Final Words
Multi-omics integration is reshaping R&D, diagnostics, and precision therapeutics. By synthesizing genomics, transcriptomics, proteomics, and metabolomics, researchers gain a panoramic view of biology that single-omics simply cannot deliver.
Biostate AI makes that vision attainable today. With cost-disruptive sequencing, automated analytics, and AI-driven interpretation, the platform democratizes multi-omics for teams of any size while upholding scientific rigor and regulatory standards.
Ready to accelerate discovery with affordable, AI-enhanced sequencing and seamless data integration? Get in touch and put multi-omics within reach.
FAQs
1. Can multi-omics data integration help uncover rare or counterintuitive biological relationships?
Absolutely. Multi-omics integration doesn’t just confirm known pathways, it often exposes unexpected correlations and previously hidden mechanisms that single-omics approaches may miss. For instance, joint analysis of genomics, transcriptomics, and metabolomics data can unravel cause-effect relationships across biological layers, sometimes leading to insights about disease subtypes or atypical responses to treatments.
2. What happens if key biomolecular data are missing or only partially available?
Missing data is a frequent and tricky problem in multi-omics. Many integration methods require complete datasets, but recent advances allow analysis to proceed even with partially observed cases, reducing the bias of imputation and leveraging partially missing data in model frameworks. However, these approaches may demand higher computational resources and can still be affected by biases if the missingness is not random.
3. Is it possible to integrate multi-omics datasets from separate studies or inconsistent sample groups?
Yes, but with major caveats. Integrating datasets collected from different cohorts or using various technologies introduces sample heterogeneity, batch effects, and non-uniform data structures. Some modern computational approaches—like bi-dimensional integration—try to harmonize structures both across omics types and sample groups. Still, successful integration requires careful preprocessing (e.g., scaling, normalization) and often sophisticated statistical modeling to mitigate inconsistencies.
4. Does more data always mean better results in multi-omics integration?
Not necessarily. While having larger, more comprehensive datasets increases the possibility of novel discoveries, it also escalates complexity, computational demands, and the risk of overfitting. Large numbers of features but comparatively few samples (the “curse of dimensionality”) can undermine predictive power. Strategies like dimensionality reduction, feature selection, and integration-specific model tuning are essential to maintain meaningful results.