
Writing complementary RNA sequences from DNA is essential in molecular biology for understanding gene expression and developing RNA-based therapies. As sequencing technologies and bioinformatics tools advance, precision in RNA sequence derivation becomes increasingly important.
The global RNA sequencing market is expected to grow at a CAGR of 16.6% by 2028, highlighting the growing importance of RNA sequencing in research. These developments help refine the writing of complementary RNA sequences, improving accuracy in transcriptomic studies and gene expression profiling.
This article explores the latest techniques, technologies, and tools for writing complementary RNA sequences from DNA.
Understanding DNA and RNA Nucleotides
DNA consists of four nucleotides: A, T, C, and G, which pair to form its double-helix structure. The template strand of DNA serves as the blueprint for RNA synthesis. Understanding DNA’s structure is essential for writing complementary RNA sequences.
1. DNA Structure and Nucleotides
DNA is composed of four nucleotides: Adenine (A), Thymine (T), Cytosine (C), and Guanine (G). These nucleotides form the building blocks of the double-helix structure, with A always pairing with T, and C always pairing with G via hydrogen bonds, ensuring the stability of the DNA molecule.
The sequence of these nucleotides encodes genetic information used for protein synthesis. It’s crucial to understand that DNA strands run in opposite directions (3’ to 5’ and 5’ to 3’), and only one strand—the template strand—serves as the blueprint for RNA synthesis.
2. RNA Nucleotides and the Role of Uracil
In contrast to DNA, RNA consists of four nucleotides: Adenine (A), Uracil (U), Cytosine (C), and Guanine (G). The critical difference here is that Uracil (U) replaces Thymine (T) in RNA. During transcription, the RNA is synthesized by pairing A with U, T with A, C with G, and G with C, effectively creating a complementary RNA sequence where Uracil replaces Thymine in the RNA strand.
3. Base Pairing Rules for RNA
The process of writing a complementary RNA sequence relies on applying the correct base-pairing rules between DNA and RNA. These rules are:
- DNA Adenine (A) pairs with RNA Uracil (U)
- DNA Thymine (T) pairs with RNA Adenine (A)
- DNA Cytosine (C) pairs with RNA Guanine (G)
- DNA Guanine (G) pairs with RNA Cytosine (C)
The substitution of Uracil (U) in RNA for Thymine (T) in DNA is crucial to this process. While Thymine is absent in RNA, Uracil takes its place and forms base pairs with Adenine, allowing for the transcription process to accurately produce RNA molecules that reflect the DNA template’s genetic code.
Step-by-Step Process for Writing Complementary RNA Sequence
Writing complementary RNA sequences from a DNA strand is straightforward but requires attention to detail to ensure the accuracy of transcription. Here’s a comprehensive, step-by-step guide:
Step 1: Identify the Template Strand
The first step is to identify the template strand of the DNA. Remember, DNA is double-stranded, with the strands running in opposite directions (antiparallel). Only one strand—the template strand—will serve as the blueprint for RNA synthesis.
- Template strand orientation: The RNA will be synthesized in the 5’ to 3’ direction, so the DNA strand that is read from 3’ to 5’ is the template.
- Coding vs. Non-Coding strand: The template strand is also known as the antisense or non-coding strand, while its complement is the coding or sense strand.
Step 2: Apply Base Pairing Rules
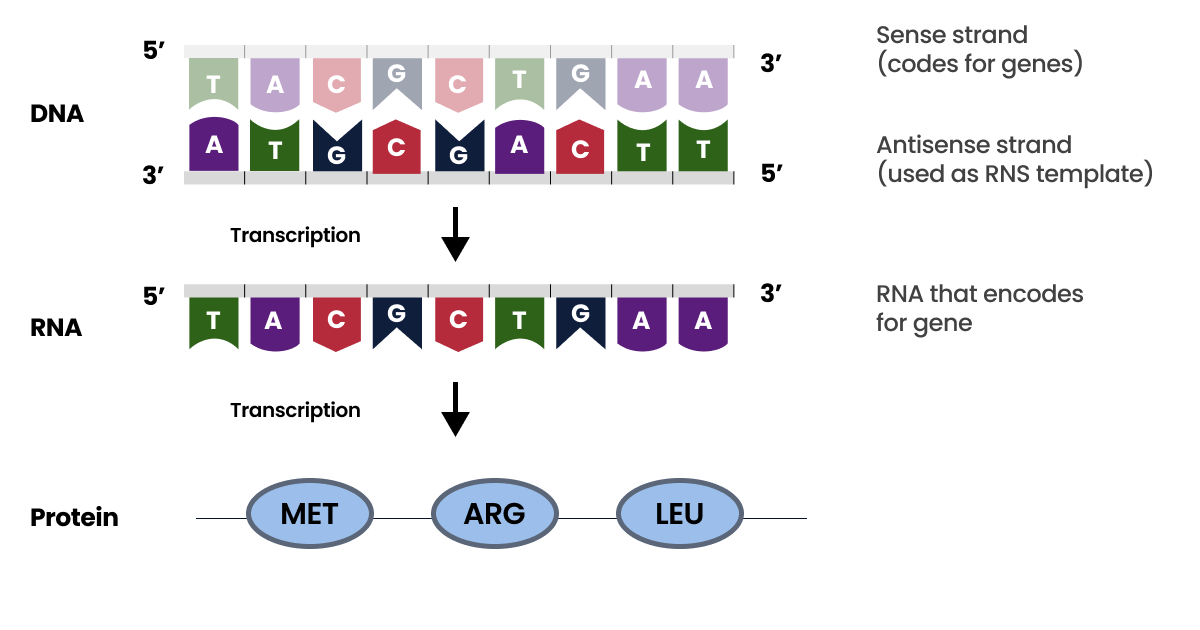
The image effectively illustrates the central concept of writing complementary RNA sequences, showing how DNA serves as a template for RNA, and how this process is essential for the synthesis of proteins.
After identifying the template strand, the next step is to transcribe the complementary RNA sequence. You apply the base pairing rules, where:
- DNA A pairs with RNA U
- DNA T pairs with RNA A
- DNA C pairs with RNA G
- DNA G pairs with RNA C
Starting from the 3’ end of the DNA template strand, write the corresponding RNA bases in the 5’ to 3’ direction.
Example:
DNA strand (3’ to 5’): TAC GGT AGC
Corresponding RNA strand (5’ to 3’): AUG CCA UCG
To ensure accurate RNA sequence generation following these base-pairing rules, researchers can turn to comprehensive RNA sequencing services like Biostate AI. Offering an affordable, end-to-end solution, Biostate AI covers everything from RNA extraction to sequencing and data analysis.
This streamlined process helps ensure the precise writing of complementary RNA sequences, which is crucial for understanding gene expression in research and clinical applications.
Step 3: Remember the Directionality
While the DNA template strand is read in the 3′ to 5′ direction, RNA is synthesized in the 5’ to 3’ direction. This is crucial for ensuring that your complementary RNA sequence is written correctly.
Example:
DNA (3’ to 5’): AGT CCG
Complementary RNA (5’ to 3’): UCA GGC
The RNA strand will always run opposite to the DNA template strand in terms of directionality.
Step 4: Add Functional Modifications (If Applicable)
For mRNA, additional modifications are made to the ends of the RNA strand to enhance stability and ensure efficient translation. These modifications are essential for RNA’s functionality in the cellular context:
- 5’ Cap: A methylated guanine nucleotide is added to the 5’ end of mRNA to protect it from degradation and aid ribosome binding during translation.
- 3’ Poly-A Tail: A string of adenine nucleotides is added to the 3’ end of mRNA, enhancing stability, facilitating nuclear export, and improving translation efficiency. These modifications are vital when writing complementary RNA sequences for practical applications, such as mRNA vaccines and gene therapy.
These modifications are crucial for the functionality of mRNA in the cellular context.
Step 5: Account for RNA Editing
RNA editing can alter the nucleotide sequence after transcription, adding another layer of complexity to complementary RNA sequence determination. Techniques like CRISPR-Cas9-based RNA editing are emerging as important tools in modifying RNA sequences for therapeutic purposes.
- A-to-I Editing: Adenosine is edited into inosine, which is recognized as guanosine by ribosomes.
- C-to-U Editing: Cytidine is converted into uridine, affecting codon usage.
Detecting these editing events requires careful analysis using tools like REDItools or specialized algorithms.
For instance, writing complementary RNA sequences from a DNA strand follows the base-pairing rules, where DNA is transcribed into RNA. In the case of tuberculosis, RNA-Seq was used to identify gene expression changes by analyzing the complementary RNA sequences transcribed from the DNA of patients.
This process is crucial for understanding disease progression and developing targeted therapies, highlighting the importance of accurate RNA sequence derivation from DNA.
Advanced Tools and Technologies for Complementary RNA Sequence Writing
With the rise of high-throughput sequencing and computational tools, writing complementary RNA sequences has become more precise and efficient. Advanced methods such as RNA-Seq and Nanopore Sequencing are at the forefront of RNA research, providing a more comprehensive view of RNA sequences, including rare transcript variants and RNA modifications.
1. RNA-Seq
RNA-Seq is an advanced sequencing technology that provides high-throughput analysis of RNA sequences. It allows for the identification of complementary RNA sequences across the entire transcriptome, detecting various RNA isoforms resulting from alternative splicing and RNA modifications, offering a more complete understanding of gene expression.
Platforms like Biostate AI offer comprehensive RNA-Seq services, covering RNA extraction, library preparation, sequencing, and data analysis. Their affordable, end-to-end service streamlines the entire RNA-Seq process, making it more accessible and efficient for researchers working on both large-scale studies and targeted research applications.
By integrating these advanced RNA sequencing services, researchers can ensure accurate and high-quality complementary RNA sequence derivation, essential for understanding gene expression and disease progression.
2. Nanopore Sequencing
Nanopore sequencing allows for direct sequencing of RNA without the need for cDNA conversion, offering a unique advantage in analyzing RNA modifications like m6A (N6-methyladenosine).
Additionally, long-read sequencing technologies, such as PacBio or Oxford Nanopore, provide deeper insights into RNA sequence complexity, helping in the analysis of long non-coding RNAs or challenging regions.
3. Bioinformatics Tools
To handle large RNA datasets, bioinformatics tools like HISAT2, STAR, Cufflinks, and StringTie are essential for efficient RNA-Seq analysis. These tools allow you to align reads to the reference genome, identify novel transcripts, and quantify gene expression levels. Additionally, DESeq2 and edgeR are used for differential expression analysis, helping to understand how RNA sequences change under different conditions.
Computational Tools for Complementary RNA Sequence Analysis
As the complexity of RNA sequence analysis increases, computational tools have become essential for accurately writing complementary RNA sequences from DNA templates.
These bioinformatic resources help researchers manage the large datasets generated by high-throughput sequencing technologies and ensure that the final RNA sequences are both accurate and biologically meaningful.
Below are some of the key computational tools used in RNA sequence analysis:
1. BLAST (Basic Local Alignment Search Tool)
BLAST is one of the most widely used sequence alignment tools in bioinformatics. It helps researchers compare newly determined complementary RNA sequences against known sequences in genomic databases, making it easier to identify similarities and functional regions within the RNA transcript.
BLAST can also be used to identify conserved motifs or regulatory elements that might have functional significance in the RNA sequence. Additionally, it plays a vital role in primer design for RT-PCR experiments, ensuring the amplification of the desired complementary RNA sequence.
2. RNAfold and Mfold
When writing complementary RNA sequences, it is crucial to understand the secondary structure of the RNA molecule, as it influences its stability, processing, and function. Tools like RNAfold and Mfold are specifically designed to predict RNA secondary structures based on sequence data.
These programs calculate the minimum free energy (MFE) structure of RNA, helping researchers predict how the RNA will fold into stem-loop formations or hairpins, which are important for RNA stability and function. Understanding these structures is vital for interpreting how complementary RNA sequences will behave in the cellular environment.
3. RNA-Seq Analysis Pipelines
For large-scale RNA sequencing projects, specialized software suites like TopHat, HISAT2, Cufflinks, and StringTie are invaluable for analyzing RNA-Seq data and writing accurate complementary RNA sequences. TopHat and HISAT2 are tools used for aligning RNA-Seq reads to a reference genome, allowing researchers to pinpoint the exact location and orientation of RNA transcripts.
Once the reads are aligned, Cufflinks and StringTie help assemble the transcriptome and quantify gene expression levels. Furthermore, DESeq2 and edgeR are used for differential expression analysis, allowing researchers to identify changes in RNA sequence expression across different conditions or treatments.
The analysis of RNA modifications like m6A (N6-methyladenosine) is becoming increasingly important in understanding gene regulation. Bioinformatics tools such as METTL3 and m6A-seq are used to detect and map RNA modifications on the complementary RNA sequence.
These tools help researchers explore how modifications impact gene expression and are critical for understanding cellular processes in diseases like cancer and neurological disorders.
Challenges in Writing Complementary RNA Sequences

While the process of writing complementary RNA sequences from a DNA template may seem straightforward, several challenges can complicate the task, especially as the field of RNA sequencing becomes more sophisticated. Here are some of the most common hurdles faced by researchers:
1. Template Strand Identification
In complex genomes, determining the correct template strand can sometimes be ambiguous, particularly when genes overlap or are located close to each other. Misidentifying the template strand can lead to incorrect RNA sequence synthesis.
Researchers typically use several strategies to address this, including promoter analysis, experimental validation (such as RNA-Seq), and bioinformatic methods like GeneMark or FGENESH, which help predict transcription direction and confirm the correct strand for RNA synthesis.
2. Alternative Splicing
Alternative splicing allows a single gene to generate multiple RNA isoforms by varying which exons are included in the final mRNA. This introduces significant complexity when writing complementary RNA sequences, as the final mRNA can vary widely depending on which splice forms are present.
Researchers must carefully account for all potential splicing events using specialized tools like rMATS or DEXSeq to accurately represent the diverse RNA isoforms generated from a single gene.
3. RNA Editing
RNA editing can alter the nucleotide sequence after transcription, adding another layer of complexity to complementary RNA sequence determination.
For example, A-to-I editing and C-to-U editing can change the codons and impact protein translation. Detecting these editing events, particularly in large datasets, requires careful analysis using tools like REDItools or specialized algorithms that predict RNA editing sites. These modifications must be factored in to ensure that the complementary RNA sequence reflects the true functional diversity of the RNA transcript.
Conclusion
Writing complementary RNA sequences from a DNA strand requires precision and attention to detail, with the application of base-pairing rules being crucial for accurate transcription.
As RNA research continues to advance, leveraging cutting-edge sequencing technologies and bioinformatics tools enhances both the accuracy and efficiency of deriving complementary RNA sequences. These technological advancements pave the way for breakthroughs in gene expression analysis and therapeutic development.
Biostate AI offers a comprehensive RNA-Seq service that includes RNA extraction, library preparation, sequencing, and data analysis. This end-to-end service provides an efficient and cost-effective solution, ensuring high-quality results that are essential for both academic research and clinical applications in RNA sequencing.
Disclaimer
The information present in this article is provided only for informational purposes and should not be interpreted as medical advice. Treatment strategies, including those related to gene expression and regulatory mechanisms, should only be pursued under the guidance of a qualified healthcare professional.
Always consult a healthcare provider or genetic counselor before making decisions about your research or any treatments based on gene expression analysis.
Frequently Asked Questions
1. What is the RNA sequence complementary to the DNA sequence?
The RNA sequence complementary to a DNA strand is synthesized during transcription, following base-pairing rules. For example, if the DNA sequence is 3′-ATG CCG-5′, the complementary RNA sequence will be 5′-UAC GGC-3′, with Uracil (U) replacing Thymine (T).
2. What is the complementary strand of mRNA to DNA?
The complementary strand of mRNA to DNA is transcribed from the antisense (non-coding) strand of DNA. The mRNA is synthesized using the base-pairing rules: Adenine (A) with Uracil (U), Thymine (T) with Adenine (A), Cytosine (C) with Guanine (G), and Guanine (G) with Cytosine (C).
3. What will be the RNA codon for ATG base sequence of DNA?
The RNA codon for the DNA sequence ATG will be UAC. This is because the base-pairing rule for DNA’s Adenine (A) pairs with Uracil (U) in RNA, and Thymine (T) pairs with Adenine (A) in RNA.
4. How to write a complementary DNA sequence?
To write a complementary DNA sequence, follow the base-pairing rules: Adenine (A) pairs with Thymine (T), and Cytosine (C) pairs with Guanine (G). For example, if the DNA sequence is 5′-ATG-3′, the complementary sequence will be 3′-TAC-5′.